RSpecで複数の指定行を実行する方法
はじめに

RSpecで特定のケースのみを「複数」実行したい状況が生じたためメモ.
やり方
行指定オプションを複数回指定する.
$ rspec [file_name] --line_number [line_number_1] --line_number [line_number_2]
略記式で以下のようにも記述できる.
$ rspec [file_name]:[line_number_1]:[line_number_2]
例えば,デグレでhoge_spec.rbにおけるx行目とy行目のit文がredになってしまい,実装修正後にgreenになっていることを確認するとき,以下のように記述すればOK.
$ rspec hoge_spec.rb:x:y
また,複数ファイルにわたる場合でも記述できる.
$ rspec hoge_spec.rb:x:y fuga_spec.rb:z
実際の開発時には,他オプションも付けて以下のように実行すると良さそう.*1 *2 *3 *4
$ rspec -fd -c --seed 1234 --fail-fast hoge_spec.rb:x:y fuga_spec.rb:z
参考
- Felix Clack — Run single and multiple lines in RSpec - http://felixclack.com/post/49917595185/run-single-and-multiple-lines-in-rspec
SRP(単一責任原則)とCC(循環的複雑度)によるコンポーネント内の技術的負債の定量化
はじめに
ソースコードを静的解析することでRailsのコンポーネント(単一ファイル)の技術的負債を定量化します.
方針はこちらの記事*1に従って行います.
なお,SRPの算出はgit blameを用いて*2行い,CCの算出はrubocopのMetrics/CyclomaticComplexityを用いて行います.
# ref: 第8回 Perlによる大規模システム開発・設計のツボ(3):Perl Hackers Hub|gihyo.jp … 技術評論社 # http://gihyo.jp/dev/serial/01/perl-hackers-hub/000803 # コンポーネントの単一責務性の違反指数(SRP) # SRP=R+U+((L/100)-5) # R:修正リビジョンのユニーク数 # U:修正ユーザのユニーク数 # L:モジュールのライン数 function get_SRP() { local target_filepath=$1 echo $(( \ $(git --no-pager blame --line-porcelain $target_filepath | sed -n 's/^summary //p' | sort | uniq -c | sort -rn | wc -l) + \ $(git --no-pager blame --line-porcelain $target_filepath | sed -n 's/^author //p' | sort | uniq -c | sort -rn | wc -l) + \ ( $(cat $target_filepath | wc -l) / 100 - 5) \ )) } # コンポーネントの循環的複雑度(CC) # CC=循環的複雑度が20を超えるメソッド数 function get_CC() { local target_filepath=$1 echo $( \ rubocop --format simple --only Metrics/CyclomaticComplexity --config <(echo -e "CyclomaticComplexity:\n Max: 20") $target_filepath | grep 'Cyclomatic complexity' | wc -l \ ) } # コンポーネントの負債指数(P) # P=SRP×CC+(SRP+CC) function get_P() { local srp=$1 local cc=$2 echo $(( $srp * $cc + ( $srp + $cc ) )) } # コンポーネントの負債指数(P)が大きい順に "P SRP CC ファイル名" を標準出力 for file in `git ls-files app lib | grep -E '\.rb$'`; do _srp=$(get_SRP $file) _cc=$(get_CC $file) echo $( get_P $_srp $_cc ) $_srp $_cc $file done | tee technical_dept_result.log | sort -k1,1 -nr
※gistはこちら*3
関連する過去記事
ni66ling.hatenadiary.jp ni66ling.hatenadiary.jp
*1:第8回 Perlによる大規模システム開発・設計のツボ(3):Perl Hackers Hub|gihyo.jp … 技術評論社 - http://gihyo.jp/dev/serial/01/perl-hackers-hub/000803
*2:git blameによるSRP(単一責任原則)の定量化 - どこでも見れるメモ帳 - http://ni66ling.hatenadiary.jp/entry/2015/06/25/000444
*3:技術的負債の定量化 - https://gist.github.com/KenshoFujisaki/9cefd372c9cec0814a08
git blameによるSRP(単一責任原則)の定量化
はじめに
ソースコードを静的解析することでSRP(単一責任原則)を定量的に算出します.*1
svn blameによるSRP算出*2を参考に、git blameによる算出をshで行ってみました.
このSRP値が最大のモジュールが王様モジュールに相当します.
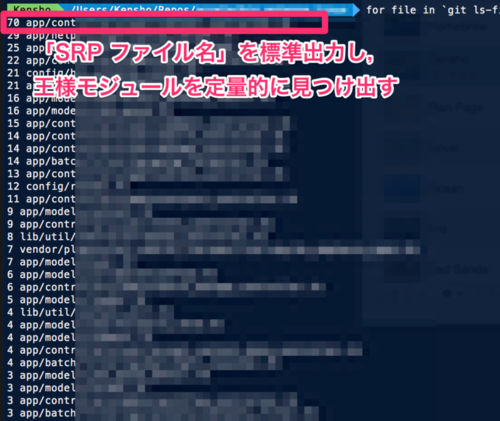
# 単一責務性の違反指数(SRP) # SRP=R+U+((L/100)-5) # R:修正リビジョンのユニーク数 # U:修正ユーザのユニーク数 # L:モジュールのライン数 function get_SRP() { local target_filepath=$1 echo $(( \ $(git --no-pager blame --line-porcelain $target_filepath | sed -n 's/^summary //p' | sort | uniq -c | sort -rn | wc -l) + \ $(git --no-pager blame --line-porcelain $target_filepath | sed -n 's/^author //p' | sort | uniq -c | sort -rn | wc -l) + \ ( $(cat $target_filepath | wc -l) / 100 - 5) \ )) $target_filepath } # SRPが酷い順(大きい順)に "SRP ファイル名" を標準出力 for file in `git ls-files app lib config vendor script | grep -E '\.rb$'`; do get_SRP $file done | sort -k1,1 -nr
※ここではrailsのリポジトリを対象にしたため,rbファイルを対象にしていますが,別言語でも全く同様に扱えます.
関連する過去記事
LDAの各変数の意味と幾何的解釈について
はじめに
LDAの仕組みについて,時間をあけるとすぐに記憶が飛んでしまうためメモ.
ここでは以下についてまとめます*1
- LDAのグラフィカルモデルにおける各変数の意味とは?
- LDAは幾何的に何をやってるのか?
LDAのグラフィカルモデル
まず,各文書についてBag of Words(BoW)表現に変換する*2.
そして,次の仮定をおく.
これをグラフィカルモデルに落としこむと下図になる*5.
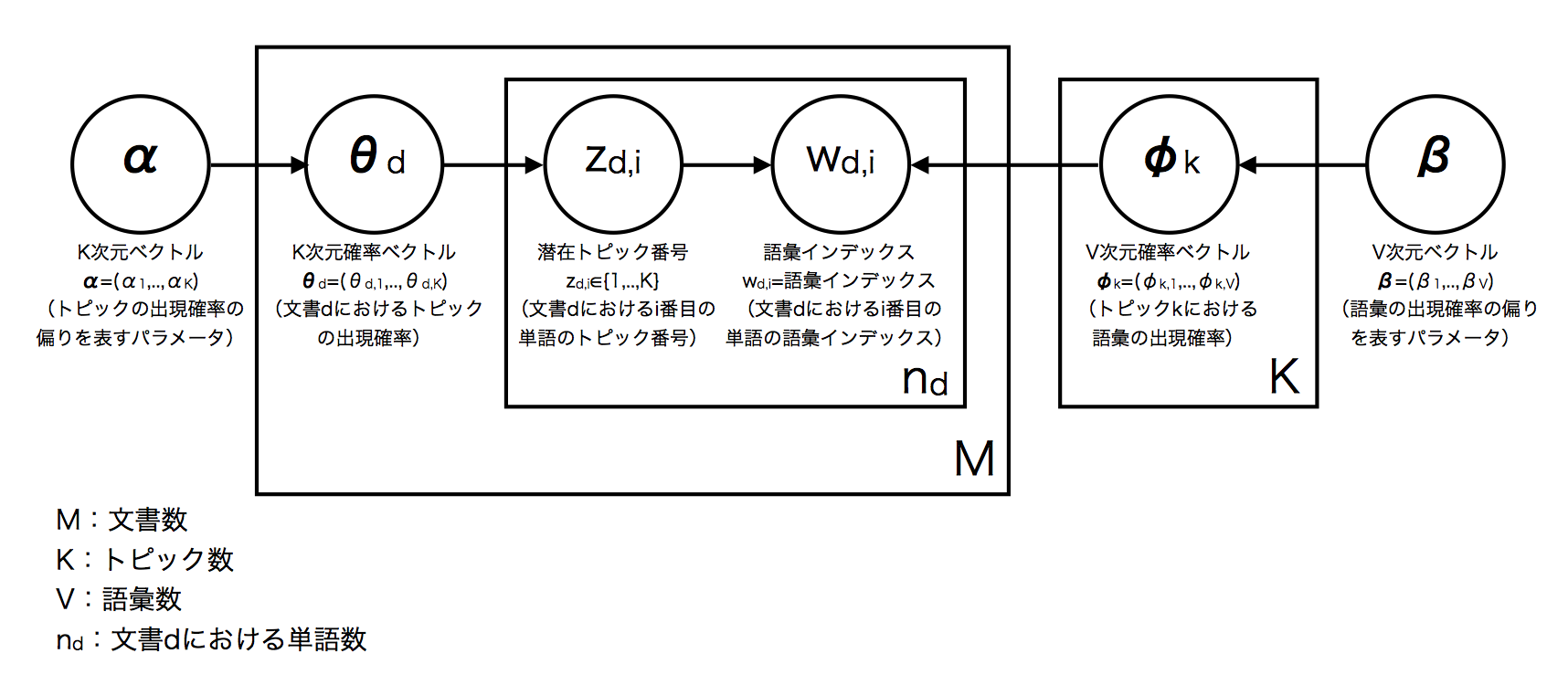
すると,グラフィカルモデルにおける各変数の意味は次のようになる.*6
:文書数
:文書集合全体におけるトピック数
:文書集合全体における語彙数*7
:文書dにおける単語数*8
:文書
における
番目の単語の語彙インデックス*9
:文書
:文書
:トピックの出現頻度の偏りを表すパラメータ*10
:トピック
における語彙の出現確率ベクトル.
:語彙の出現頻度の偏りを表すパラメータ*11
LDAの生成過程
ただし,はディリクレ分布,
は多項分布を表す.*12
また,と
はパラメータとして与える.
補足:パラメータ と
と の意味
の意味
多項分布による生成過程を考えて,
の事前分布としてディリクレ分布
,ただし
を考える.
すると,の事後分布は,
となる.
ただし,は
回試行の中で
が出現した回数.
すなわち,事前分布におけるは,事後分布では
に加算される.
したがって,はデータを観測する前の
ごとの仮想的頻度を表す.
よって,LDAにおけると
についていえば,次のようになる.
LDAの幾何的解釈
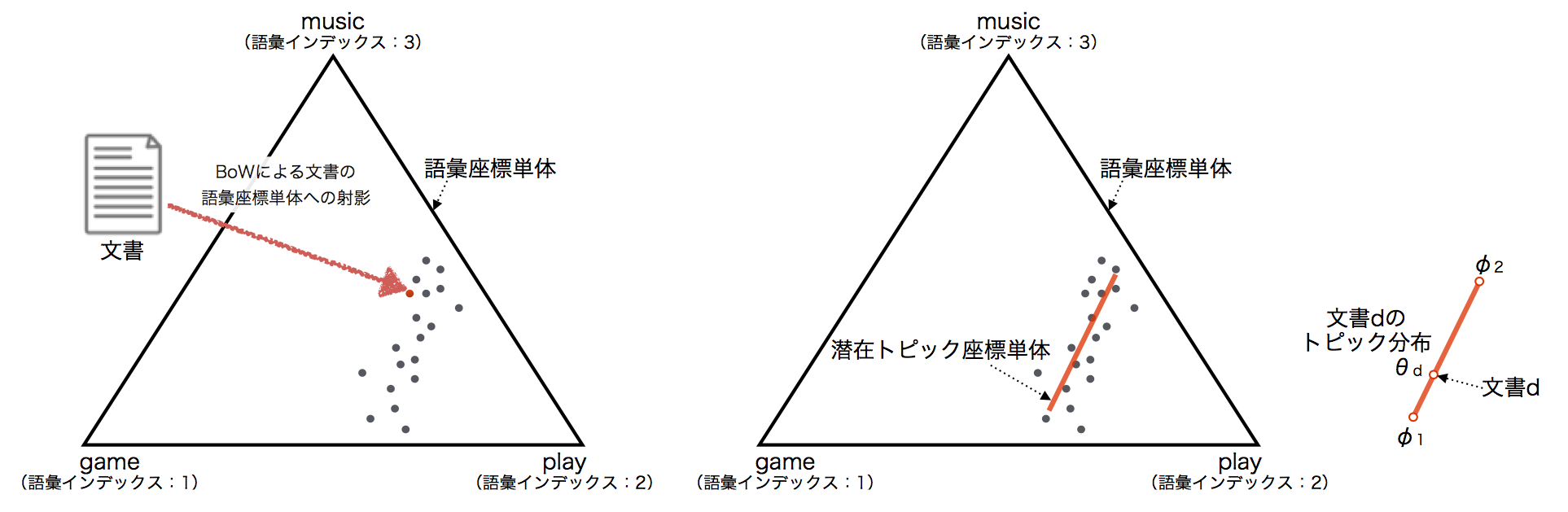 簡単のため,全文書集合における語彙数Vが3の場合を考える*13.
簡単のため,全文書集合における語彙数Vが3の場合を考える*13.
このとき,各文書をBoW表現にすることで,上図の語彙座標単体*14に射影できる.
各文書は語彙座標単体空間に偏りをもって分布していると想定*15され,より低次元に射影できるはずである.
この低次元空間(単体)を潜在トピック座標単体と呼び,その基底ベクトルがトピックとなり,トピックは語彙の出現確率分布で表現される.そして,各文書のトピック分布は,潜在トピック座標単体上の点となる.
つまり,LDAのは,文書集合の潜在トピック座標単体上への射影とみることができ,
潜在トピック座標単体は,単語座標単体よりも低次元であるため次元圧縮と見ることができる.
参考文献
")
トピックモデルによる統計的潜在意味解析 (自然言語処理シリーズ)
- 作者: 佐藤一誠,奥村学
- 出版社/メーカー: コロナ社
- 発売日: 2015/03/13
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (5件) を見る
*1:ほとんどの内容を本ページ末尾の参考文献から引っ張ってきています
*2:文書を形態素解析し,形態素のヒストグラムに変換する.例えば,文書が「もももすももももものうち」であれば,分かち書き「もも/も/すもも/も/もも/の/うち」に対して,形態素ごとにカウントした「もも:2 も:2 すもも:1 の:1 うち:1」がBoW表現である.
*3:話題.音楽,スポーツ,政治…など
*4:出現箇所が異なればその単語のトピックは異なる.例えば,「アップルが新製品を発表しました」と「バナナ,アップル,キウイのミックスジュースがうまい」の「アップル」のトピックは異なる.前者は「企業」トピックとしてのアップルであり,後者は「フルーツ」トピックとしてのアップルである.
*5:これは正確にはSmoothed LDAのグラフィカルモデル.無印LDAの場合はβが存在しない.多くの場合,LDAといえばSmoothed LDAを指すみたい.
*6:ベクトル表記に関して,上図では太字で記し,下では矢印で表記する.…はてなtex記法で太字を表現できなかった…
*7:ここでは「語彙」はユニークな形態素として呼び,一方「単語」はユニークでない形態素として呼ぶ.例えば,「もももすももももものうち」の語彙数は「もも」「も」「すもも」「の」「うち」の5つとするのに対して,単語数は「もも」「も」「すもも」「も」「もも」「の」「うち」の7つとする.
*8:語彙数とは異なるので注意
*9:語彙インデックスは語彙へのマッピング情報を持つ.例えば,語彙インデックス「3」は語彙「すもも」を表すなど
*10:要素値は大きくなるに連れて,文書集合全体においてトピック
が出現しやすくなる
*11:要素値は大きくなるに連れて,文書集合全体において語彙インデックス
の語彙が出現しやすくなる
*12:各分布の意味はこちらのスライドがわかりやすいです → 3分でわかる多項分布とディリクレ分布 - http://www.slideshare.net/stjunya/ss-29629644/4
*13:すべての文書において,登場する語彙がgame,play,musicの3つしか存在しない状況
*14:各語彙の出現確率の総和が1となるような空間
*15:単語には共起性があるから
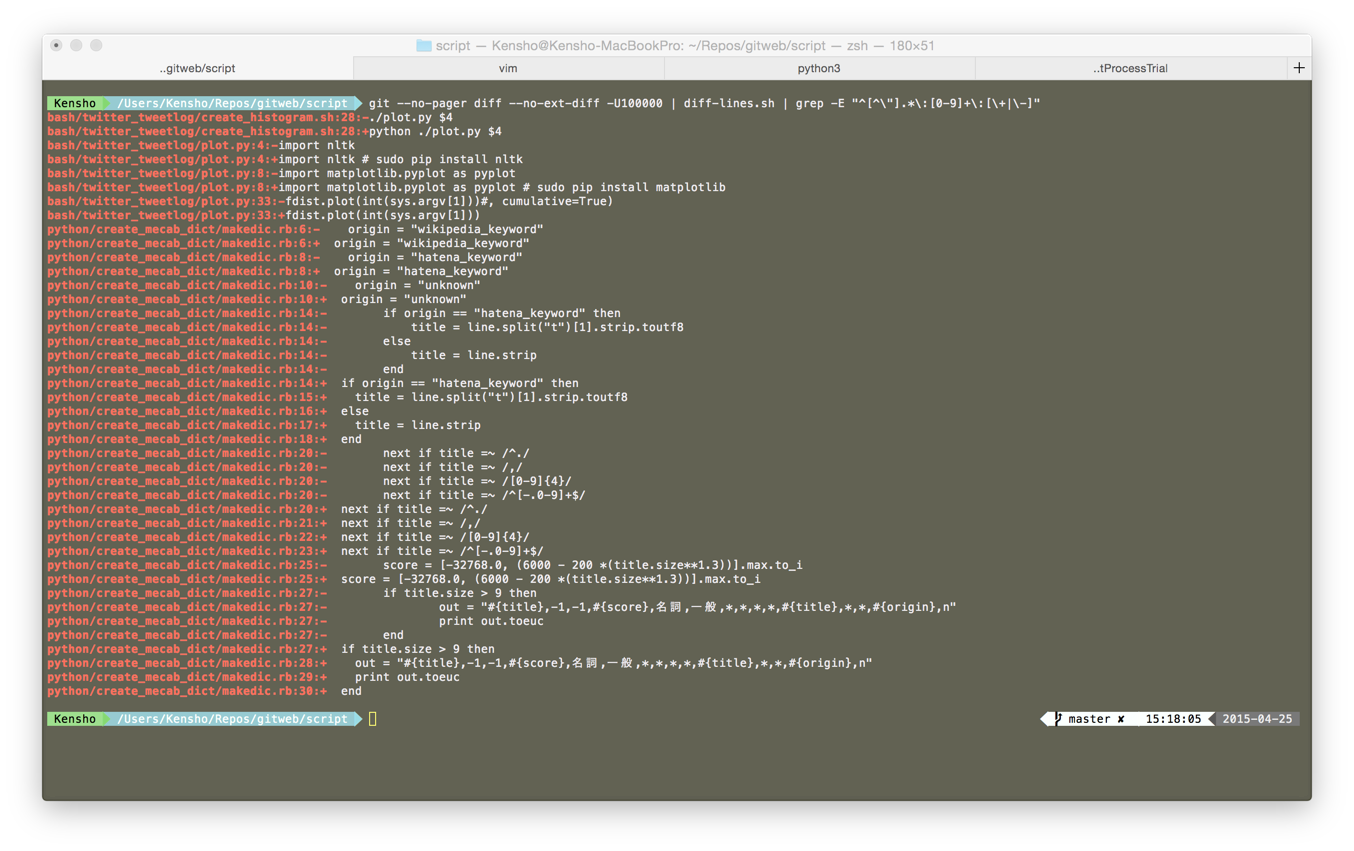
gitで変更ファイルの差分行番号を取得するには?
はじめに
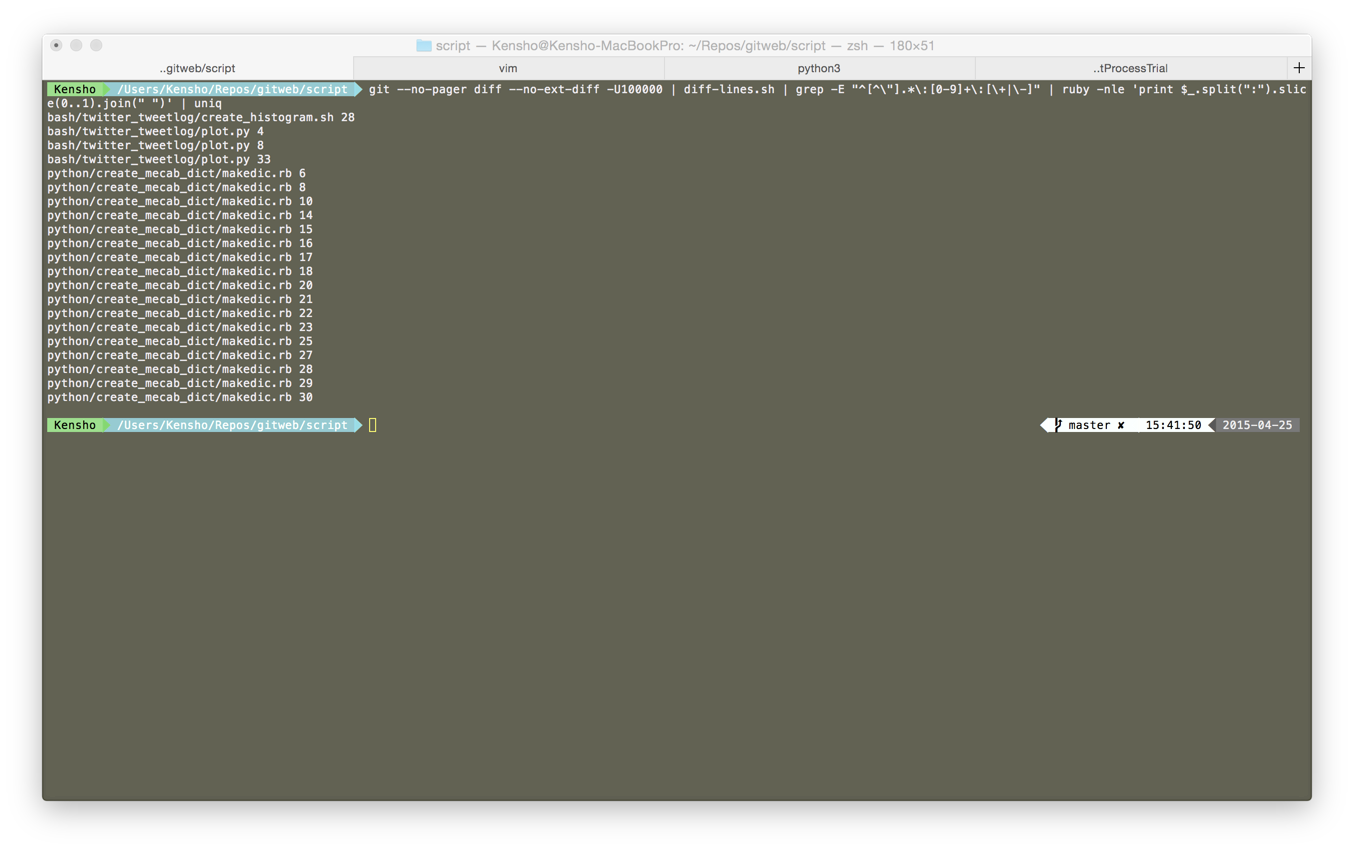
gitで変更ファイルの差分行内容とその行番号を取得したい状況が生じたためメモ(下画像は実行結果)
やりかた
git --no-pager diff --no-ext-diff -U1000000 \ | diff-lines.sh \ | grep -E "^[^\"].*\:[0-9]+\:[\+|\-]"
- 1行目について,git diffをファイル全行について標準出力*1.具体的には以下.
- --no-pagerはgit diffを標準出力するオプション.デフォルトだとpagerにlessが設定されてしまうため,パイプに渡せるように指定
- --no-ext-diffは外部diffを無効化するオプション.git diffをvimdiffで見るように設定していたため指定
- -Uは行数を表示するオプション.例えば10を設定すると差分行まわりで10行が出力される.ファイル内容について全行出力したいため大きな値1000000を指定
- 2行目について,diff-lines.shは以下とし*2,pathを通しておく.
- 3行目について,変更のある行の取得.
#!/bin/sh # diff-lines.sh numbers path= line= while read; do esc=$'\033' if [[ "$REPLY" =~ ---\ (a/)?.* ]]; then continue elif [[ "$REPLY" =~ \+\+\+\ (b/)?([^[:blank:]]+).* ]]; then path=${BASH_REMATCH[2]} elif [[ "$REPLY" =~ @@\ -[0-9]+(,[0-9]+)?\ \+([0-9]+)(,[0-9]+)?\ @@.* ]]; then line=${BASH_REMATCH[2]} elif [[ "$REPLY" =~ ^($esc\[[0-9;]+m)*([\ +-]) ]]; then echo "$path:$line:$REPLY" if [[ "${BASH_REMATCH[2]}" != - ]]; then ((line++)) fi fi done
補足
ファイル名と行番号だけで良い場合は以下のようにすればOK
git --no-pager diff --no-ext-diff -U1000000 \ | diff-lines.sh \ | grep -E "^[^\"].*\:[0-9]+\:[\+|\-]" \ | ruby -nle 'print $_.split(":").slice(0..1).join(" ")' \ | uniq
*1:Git - git-diff Documentation - http://git-scm.com/docs/git-diff
*2:Using git diff, how can I get added and modified lines numbers? - Stack Overflow - http://stackoverflow.com/questions/8259851/using-git-diff-how-can-i-get-added-and-modified-lines-numbers